以MNIST为例使用降维投影进行高维数据可视化
问题提出
现在的大多数数据集拥有越来越多的维度,而我们人类无法直观想象高维数据分布情况,也不善于同时处理多维度信息,所以怎样将高维度数据可视化成为了关键。
二、问题定义
高维数据可视化是指使用合适的方法对高维数据进行处理,或者使用合适的展示方式将高维数据以可视化的形式展现,便于我们分析数据中内在的联系。
本文将使用MNIST数据集为例通过降维投影方式进行一些探索。事实上我们已经清楚该数据集分为10类,并且每个数据都有相应的标签,我们期望降维后的数据能体现出良好的聚类表示。
数据来源
MNIST数据集是一个手写数字图片数据集,该数据集共含有70000张图片,每张图片为28*28的灰度像素。我们将28*28=784个灰度像素值视为数据的维度,可视化时随机选取10000张图片以方便呈现。
下图为其中的几张图片:
解决方案
3.1 PCA
主成分分析(PCA)是一种统计分析、简化数据集的方法。它利用正交变换来对一系列可能相关的变量的观测值进行线性变换,从而投影为一系列线性不相关变量的值,这些不相关变量称为主成分。具体地,主成分可以看做一个线性方程,其包含一系列线性系数来指示投影方向。
我们首先使用PCA(使用Scikit-Learn包)将数据降到二维并用散点图表示: 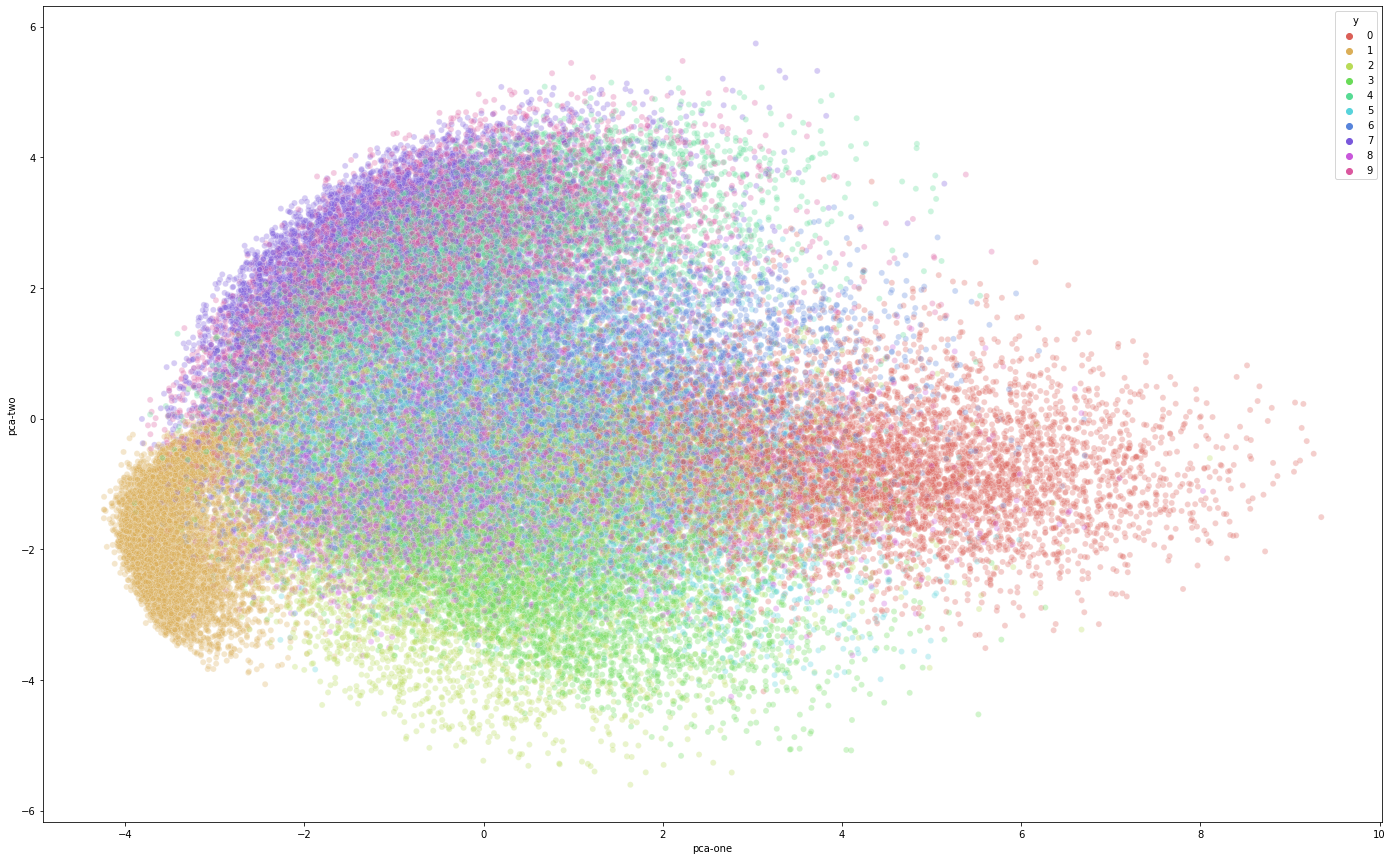
可以看到这两个维度确实保留了一些信息,特别是对像数字1等某些数字,但是其他数字的分类关系并不明晰。实际上,explained_variance_ratio_变量表明这两个维度大概保留了17%的信息,这显然不足以表示高维数据的关键结构。
3.2 t-SNE
实际上,PCA是一种线性方法,在降维过程中主要保证了不相似的点尽量远离的结构特征. 但是当高维数据处于低维非线性流形上时, 保证相似的点尽量接近更为重要, 而这在线性映射中通过难以做到。
t-SNE 可用于可视化高维数据, 它可以保留高维数据的局部特征, 同时也能揭示数据的整体结构。它的基本原理是:通过仿射变换将数据点映射到概率分布上,主要包括两个步骤:构建一个高维对象之间的概率分布,使得相似的对象有更高的概率被选择,而不相似的对象有较低的概率被选择;在低维空间里在构建这些点的概率分布,使得这两个概率分布之间尽可能的相似。
Scikit-Learn中的TSNE函数推荐维度不要太高,所以我们先使用PCA将维度降至50,50维大概保留了82%的信息,并且可以起到降噪的作用。然后我们的参数设置为perplexity=40, n_iter=300, learning_rate=’auto’,其他都保持为默认。最后得到的效果(和PCA对比):
可以看到,达到了很好的聚类效果,后续可以使用k means等简单的聚类算法即可以完成较好的分类效果。
总结与思考
作为非监督方法,t-SNE在MNIST达到这样的效果超出了我的预期,尽管如此,我们仍然需要注意t-SNE的一些缺点:
- t-SNE 对超参数很敏感
- 计算量较大(本文中300步花费了150s,CPU:AMD R5 3600)
- 高维空间数据的方差不会反映在低维表示中
- 聚类间的距离没有意义
- 随机噪声看起来不一定那么随机
- 有时候会出现一些特殊的形状